
Movie Recommendation System
Hello, I have created a Movie Recommendation project with my project partner Jay and Darshan. This project is basically working on Machine learning Techniques and concepts of Recommendation. In this blog, you can see all details about our project. So first we understand about the recommendation.
A movie recommendation system is a ML-based approach to recommend movies to particular users based on their past experiences. Let’s take an example if we like to watch action movies then the action movies, they recommend like that. The core concept of any recommendation system is users and items. For movie prediction items are movies themselves.
The primary goal of the recommendation system is to filter and predict only those movies that correspond to users most likely to watch. The ML model uses these data and based on that do predictions.
The recommender system helps to enhance the user’s experience through suggesting because there is a number of shows or movies listed on the website so from those shows or movies user will find their interest in movies or shows.
Types of Recommendation Systems:
- Content-Based
- Collaborative Filtering
- Hybrid

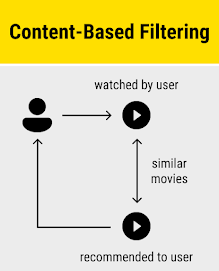
- In this project, we use content-based filtering where we recommend movies based on content watched by a user. The TMDB 5000 Movies Dataset we used to build a model, by using this dataset we create the tags for particular movies using overview, genres, keywords, cast, and crew fields and convert that tags into vectors called text vectorization to do that we use a bag of word technique, in this technique we combine all the tags and find the most frequent words. After that find, the count of that words in particular movie tags creates a vector matrix and calculate the distance between vectors if the distance is high and similarity is low so to do that we use Cosine similarity. At last, deploy the recommender system on the web using Streamlit python framework.


Technologies :
In this project, we used Pickle which is used for serializing and deserializing a Python object structure. it's the process of converting a Python object into a byte stream to store it in a file/database, maintain program state across sessions or transport data over the network.
Streamlit is an open-source app framework in Python language. To creates web apps for data science and machine learning in a short time helps. It is compatible with major Python libraries such as scikit-learn, Keras, PyTorch, SymPy(latex), NumPy, pandas, Matplotlib, etc. it is more structured and focused more on simplicity.
In data science/data analysis and machine learning tasks, Pandas which is an open-source Python package that is most widely used is built on top of another package named Numpy, which provides support for multi-dimensional arrays.
Below are the snapshots of the Movie Recommendation System
.png)
.png)
.png)




{kind=link}
0 Comments